An accuracy that was answering an easier question
I had a speech-emotion model I was proud of. The first thing I found when I rebuilt it was that its accuracy was mostly the model recognizing the 24 RAVDESS actors, not reading their emotions. It had been graded on the same people it trained on, and once I stopped letting it do that, a chunk of the accuracy went with it.
This is the honest rebuild: a speaker-independent pipeline that fuses voice and face, with every number measured on people the model has never heard or seen. The code is on GitHub and there is a live demo you can talk to. The one number I will defend by the end of this post is 78.8%, and I will show you exactly why it is worth more than that inflated score was.
The whole system in one picture
Before any of the details, here is the entire system. Two models, trained separately, that only meet at the very end when their probabilities are combined. Keep this picture in mind; every section below zooms into one piece of it.

The reason it is built as two separate models, rather than one network that swallows both, is the most interesting engineering decision in the project, and I will get to why the obvious alternative fails.
Why RAVDESS is a trap: 24 actors, two sentences
RAVDESS is a standard benchmark for emotion from speech. 24 professional actors each speak the same two sentences, "Kids are talking by the door" and "Dogs are sitting by the door", in eight emotions: neutral, calm, happy, sad, angry, fearful, disgust, surprised. That is 1440 short clips in total.
Read that again. Twenty-four people, two sentences. That tiny, repetitive structure is what makes it a trap. There is so little variety that a model can do well by memorizing voices instead of learning emotion, and the standard way people split the data lets it do exactly that.
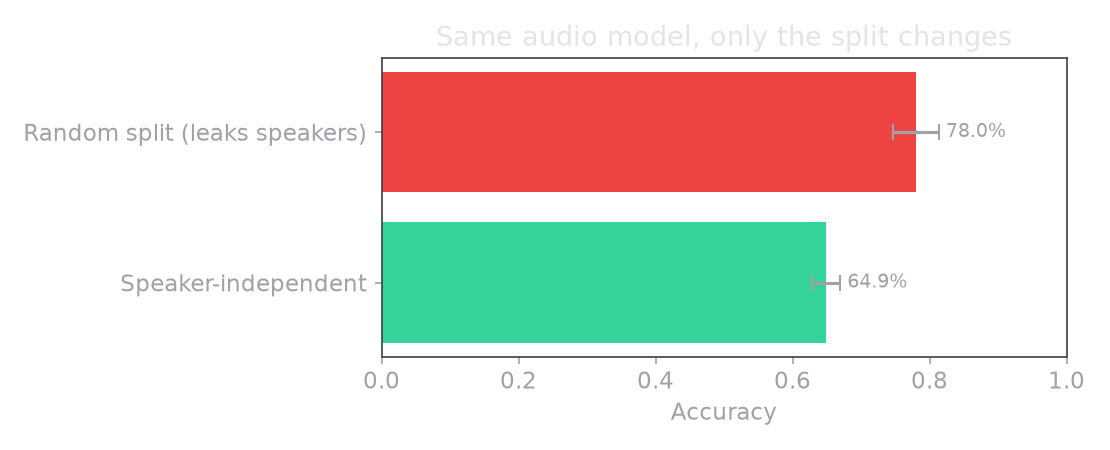
Split by clip and you measure the wrong thing
If you shuffle all 1440 clips and take a random fifth as your test set, the same actor saying the same sentence in the same emotion ends up on both sides, separated only by which of the two takes it was. The model never has to learn what anger sounds like in general. It only has to remember what actor 14 sounds like angry, because it already met actor 14 being angry in training.

I did not want to argue about this in the abstract, so I ran a controlled experiment: the same model, the same training code, the same everything, changing only the split.
Proving the split is clean, mechanically
The fix is to split by actor. I use six-fold cross-validation where each fold tests on four actors who appear in no training or validation data, balanced by gender, and four more actors are held out of each training set for early stopping. No actor is ever on two sides of a fold.
Because the entire result rests on this, I did not want to trust myself to get it right by hand. A unit test fails the build if any actor leaks across any fold:
def test_no_actor_leaks_across_splits():
for f in make_speaker_independent_folds(Config()):
assert not (set(f.train_actors) & set(f.test_actors))
assert not (set(f.val_actors) & set(f.test_actors))
assert set(f.train_actors | f.val_actors | f.test_actors) == set(range(1, 25))Is 64.9% just a bad model?
That was my first worry. Watching the honest score land at 64.9%, after the leaky split had flattered the same model to 78%, feels like failure. It is not. It lands almost exactly on the peer-reviewed, genuinely speaker-independent baseline: EmoBox (Interspeech 2024) reports 66.2% for a HuBERT-base model on RAVDESS under a comparable protocol. My 64.9% with the same encoder sitting right there is the evidence that the pipeline is honest, not broken. The 90s are the mirage; the 60s are the real floor for a base-size model. Now the job is to raise that floor without cheating.
The audio model: where emotion actually lives
The audio branch is a self-supervised speech encoder (WavLM-large) with a small head on top. Two choices in that head matter specifically for emotion, and they are worth understanding because they are where most of the honest gain comes from.

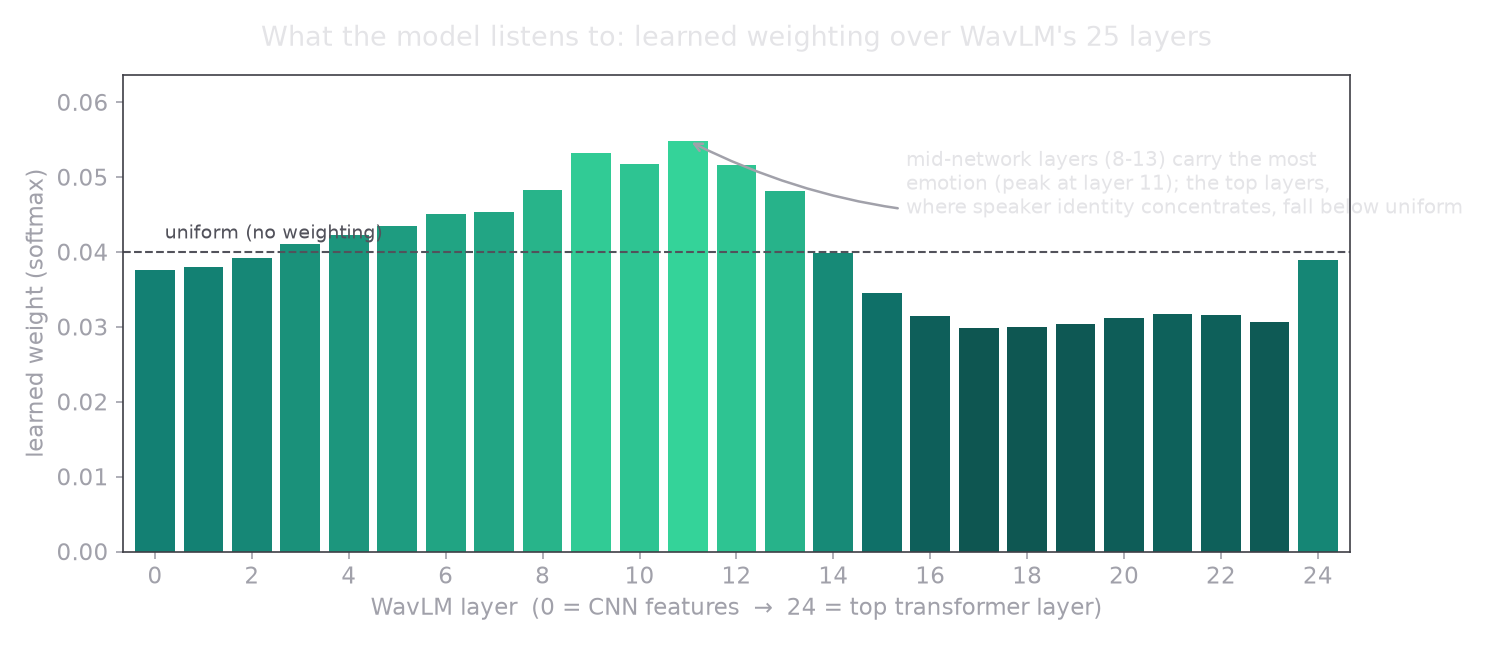
- Learnable layer weighting. Instead of using only the encoder's final layer, the head learns a softmax-weighted sum over all 25 layers. Emotion is carried in the middle layers; the final layer has drifted toward the actual words being spoken, which is what the encoder was pretrained to predict.
- Attentive statistics pooling. The head pools both the attention-weighted mean and the standard deviation over time. Affect lives in how much the tone varies, and a plain average throws that variation away.
The weighted-layer sum is a handful of lines, and the learned weights end up favoring the middle of the network, exactly as the intuition predicts:
stack = torch.stack(out.hidden_states, dim=0) # (25, B, T, H)
w = torch.softmax(self.layer_weights, dim=0) # one learnable weight per layer
hidden = (w.view(-1, 1, 1, 1) * stack).sum(0) # weighted blend of all layersAnd it does not just match the intuition in theory. These are the actual weights the head learned, read straight out of the trained checkpoint:
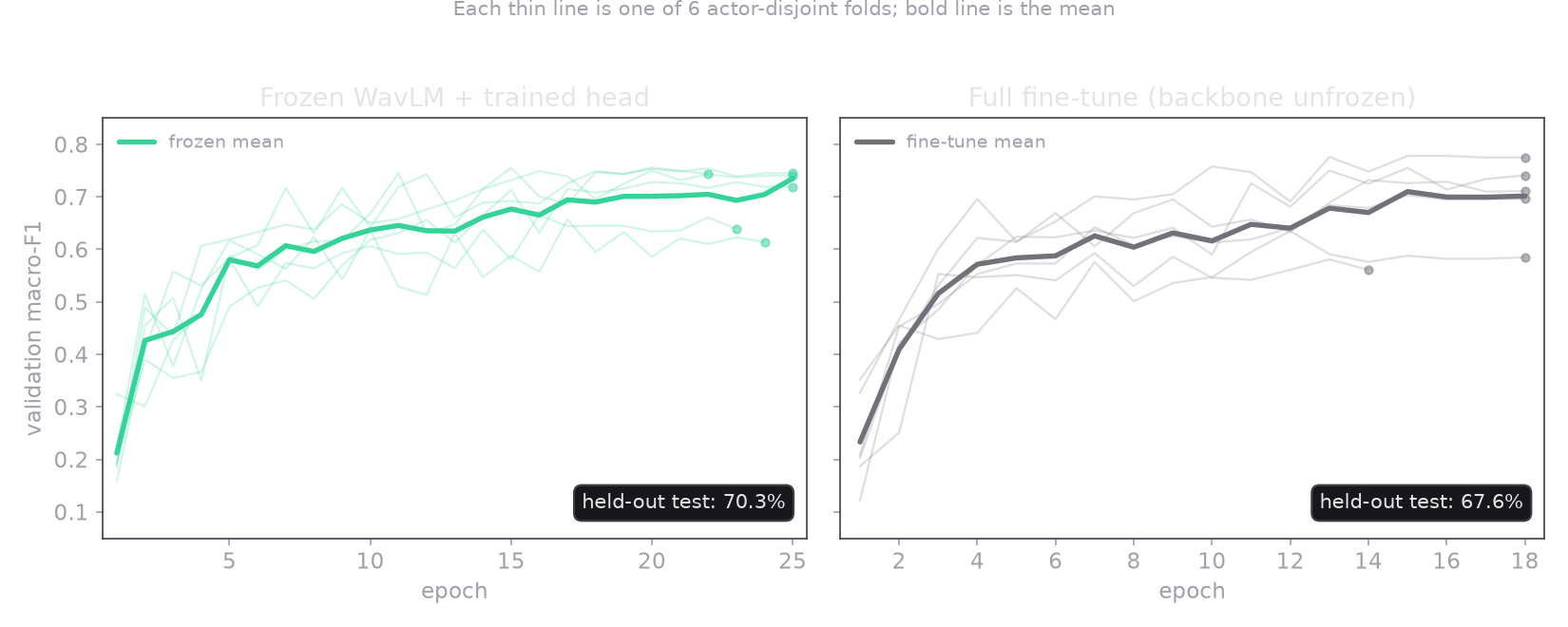
When fine-tuning loses: frozen features win on small data
Here is the result that surprised me most. The obvious move is to fine-tune the big encoder on the task. I tried it, and WavLM-large fine-tuned scored 67.6%, which is below a simple frozen-feature baseline. A 300-million-parameter model fine-tuned on 1440 clips overfits, and the speaker-independent folds are exactly where that overfitting shows. So I froze the encoder entirely and put all of the learning into the small head described above. That gave 70.3%.
The face has the same trap, in a new costume
RAVDESS is audio-visual, so the natural next step is to add the speaker's face. My first attempt made things worse, and the reason was the same lesson wearing a different costume. I had encoded each face with a standard image network trained on ImageNet, and I tested it the same way I tested the audio.

The ImageNet features scored 89% when the same faces leaked across the split but only 35% on faces the model had never seen. They were memorizing identity, not reading expressions, which is the visual version of the speaker leak. Swapping to a model trained on facial expressions shrank that gap from 54 points to 32, lifting new-face accuracy to 58%. Now the face carried something real and transferable, worth fusing.
Why the obvious fusion fails, and the one that works
With a 70% audio model and a 58% face model, fusing them should be easy. It is not. The obvious approach, one network trained on both streams at once, scored 43 to 47%, below either model alone. That is a known failure mode called modality competition: with so few clips and identities, the optimizer leans on whichever stream is easier to fit on the training data, which here was the face with its leftover identity signal, and the joint model transfers worse than just trusting the audio.

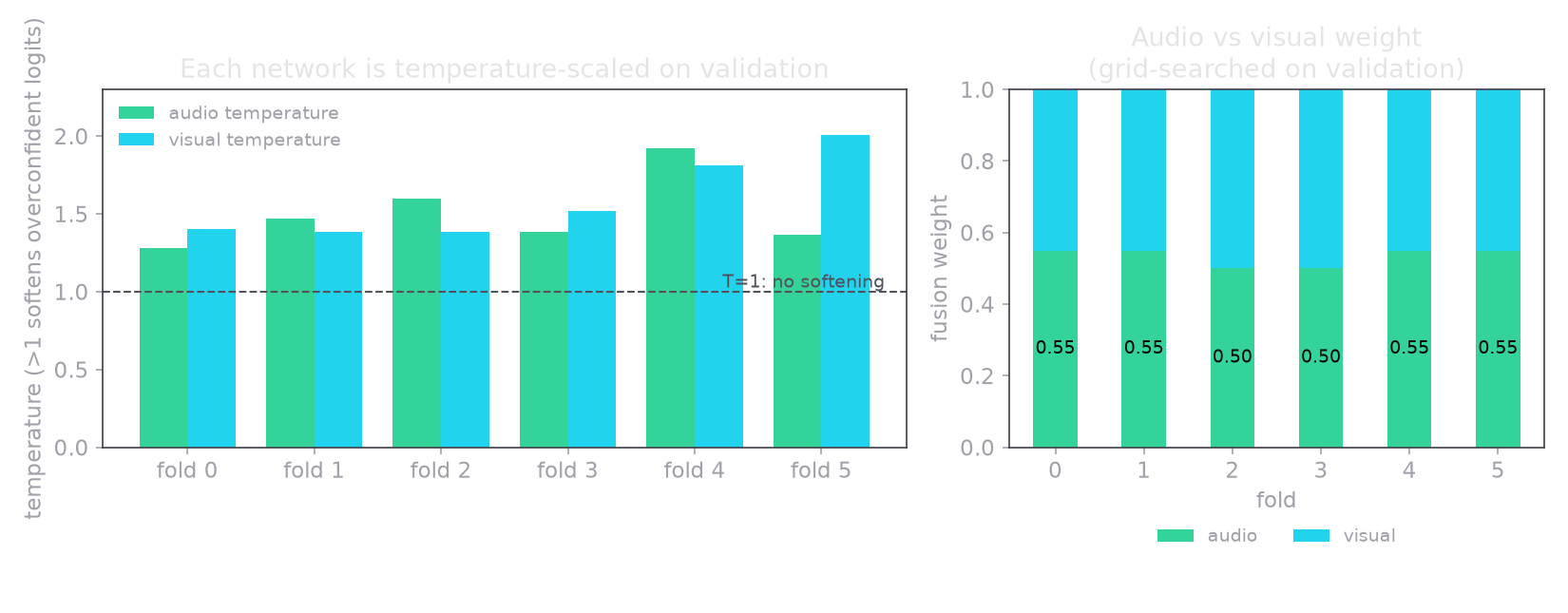
The fix is decision-level fusion, the rule that won the older audio-video emotion challenges for exactly this reason. Keep the two models separate, let each be its best, and combine only their class probabilities. Two details make the average safe instead of harmful: calibrate each model with temperature scaling so a confidently-wrong face cannot shout down a quiet-but-right voice, and choose the mixing weight on held-out validation, where audio-only (weight one) is always one of the options.

Choosing that weight on validation, never on the test set, is what separates a real gain from a fake one. Because weight one means audio only, the floor is guaranteed: late fusion can never score below the better single model.
The result: fold by fold, emotion by emotion
Put the whole arc on one axis. Every number here is speaker-independent, the mean across six actor-disjoint folds.
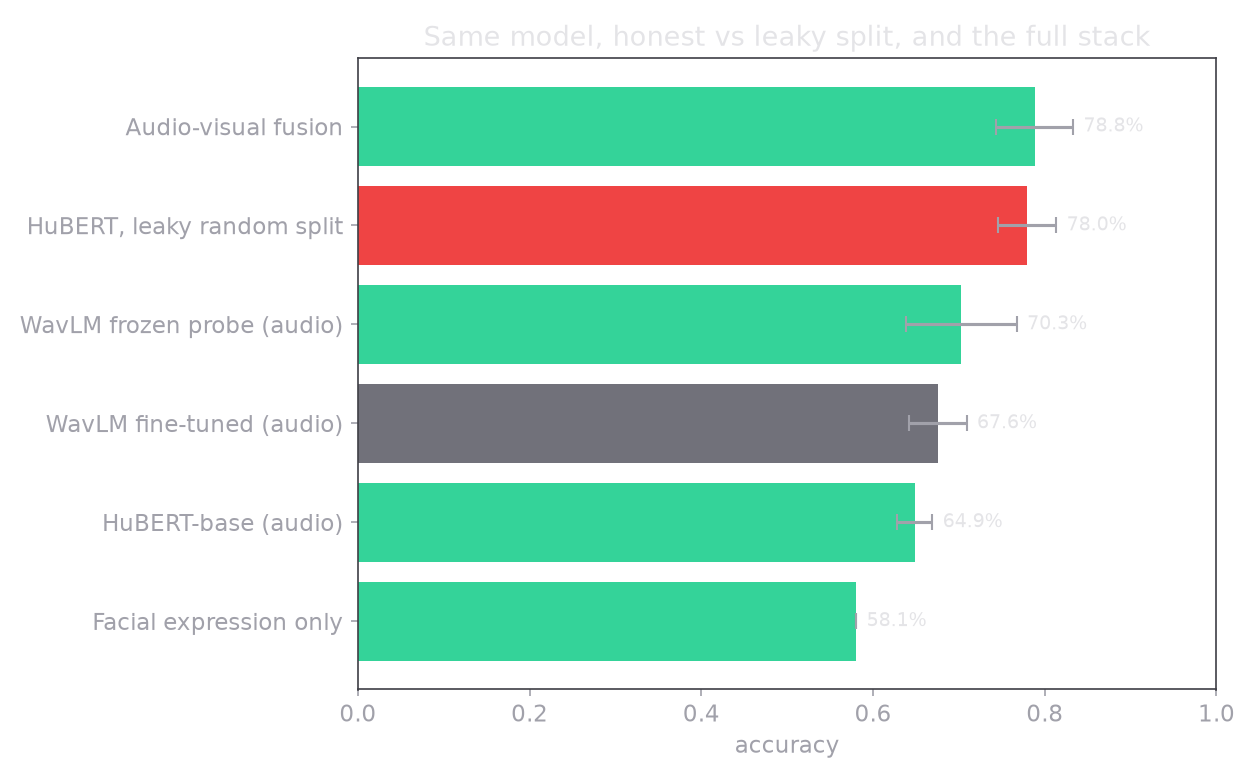
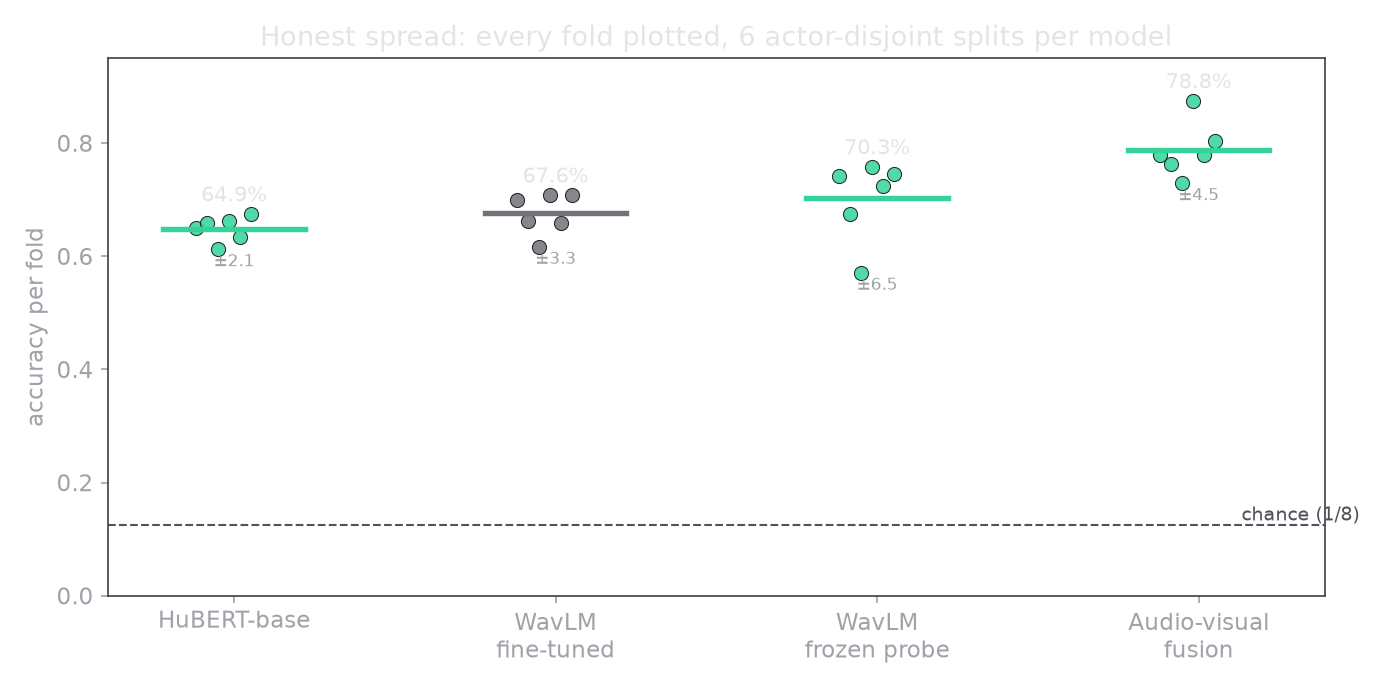
The means above hide nothing, because here is every fold behind them. The spread is real, and reporting it honestly is part of the point.
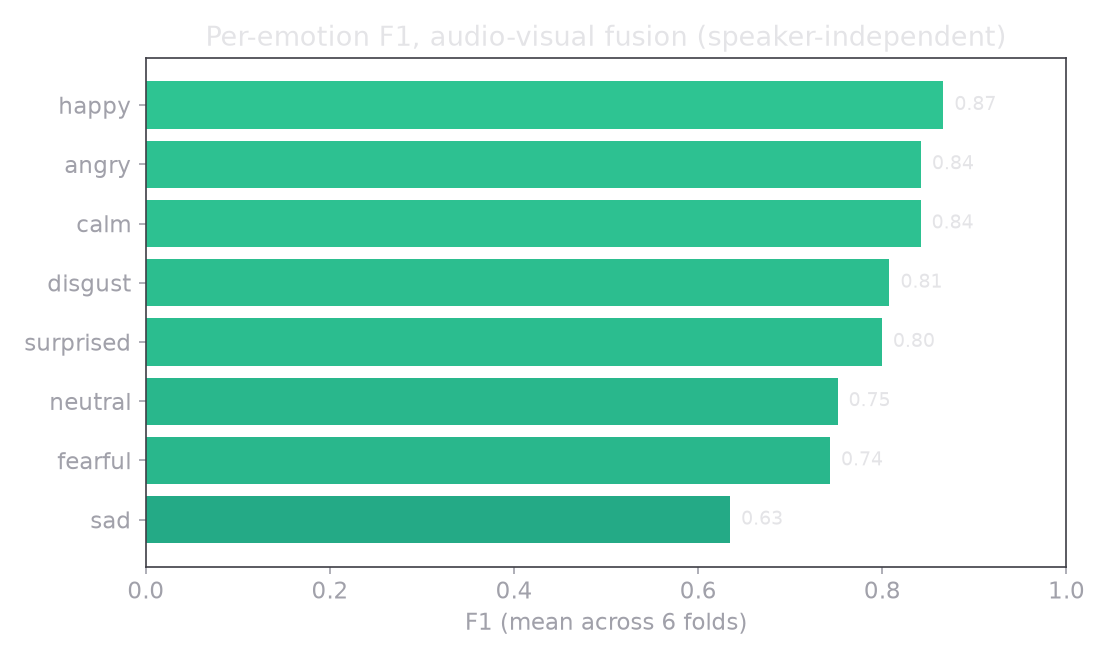
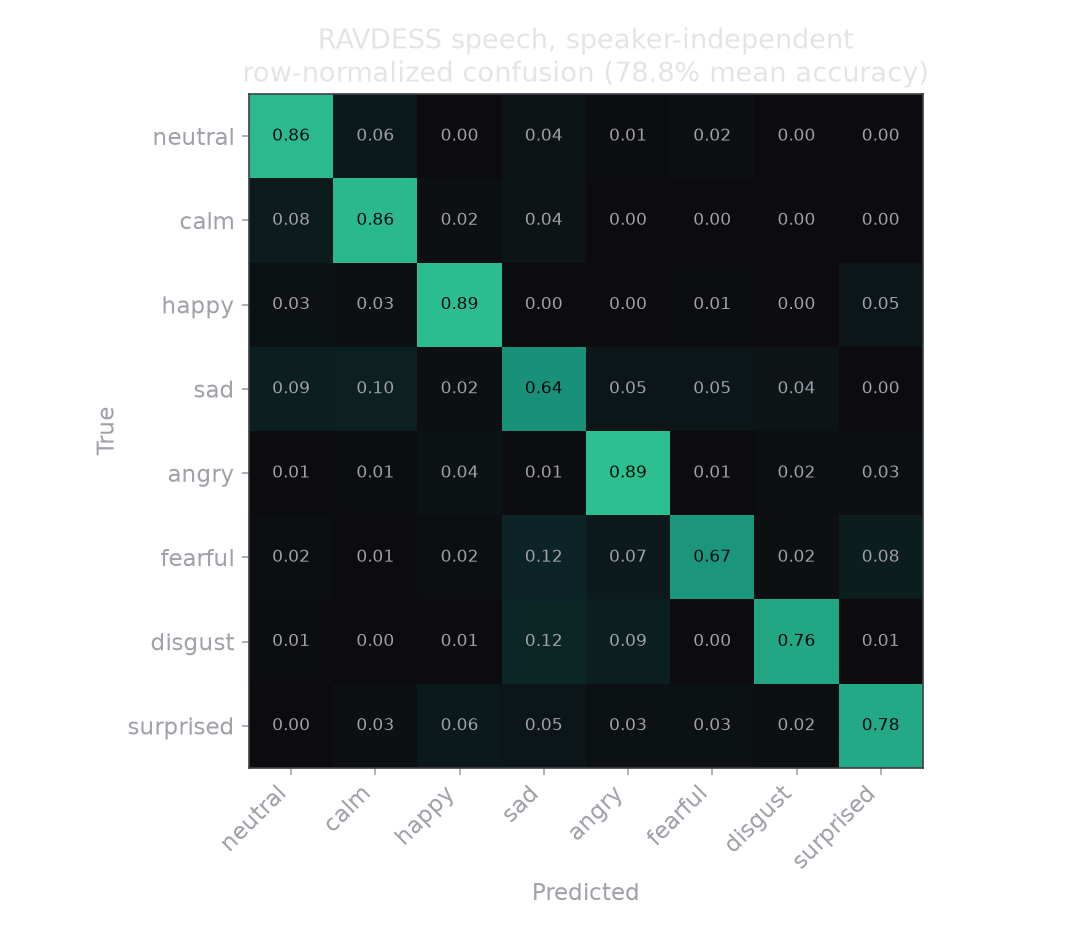
Calibrated late fusion reaches 78.8%, a real 8.5 points over the 70.3% audio model, with no leak. The face is not magic; it is a modest, honest lift that the simple combination rule is able to keep. Per emotion, the model is confident where the voice is unambiguous and hesitant where people hesitate too.
What it does not do
A model is only as honest as its limitations, so here they are plainly:
- 1440 clips and only 24 actors. The speaker-independent numbers carry a real standard deviation across folds, from about 2 points for the steadier models to 6 for the noisiest, as the per-fold plot above shows, and no amount of cleverness changes that the dataset is small.
- Acted, frontal, clean. RAVDESS emotions are performed in a studio. These numbers do not transfer directly to spontaneous, in-the-wild speech and faces.
- One corpus. Cross-dataset generalization is a separate, harder question I did not test here.
- The hosted demo runs the audio branch only. The face and fusion pipeline needs video frames and more compute than a free CPU Space, so the live demo predicts from voice alone at 70.3%.
What the rebuild was really about
In the end this taught me less about emotion and more about measurement. The first version was not dishonest on purpose; it just answered an easier question than the one I thought I was asking. "Can it read emotion in actors it already knows" is a very different, much easier question than "a person it has never met." The second one is the one that matters, and it is the one worth reporting even when the number is smaller.
So the number I stand behind is 78.8%, speaker-independent, with everything above to back it up. You can try the audio model yourself just below: record or upload a few seconds of speech and watch it predict, on a voice it has never heard.